


最新智谱AI GLM Coding优惠2026,5折大促+ 额外节日限定优惠,年付套餐仅需192元/年!
简介
GLM Coding是智谱AI最新推出的“AI编码订阅计划”,由GLM-4.5双旗舰模型驱动,一次付费即可在Claude Code、Cursor、Cline等十余款主流插件里共用超长上下文额度,无需反复充值;128K乃至1M token窗口让它能一次吞下整仓源码,秒出模块图、调用链与风险点,接手老项目零门槛;支持Python、Java、Rust等30+语言,生成准确率95%+,可边聊边重构、一键性能优化并自动输出API文档;内置@workspace项目级感知,结合RAG实时索引本地文件,精准回答“鉴权逻辑在哪”类问题,还能根据代码自动生成Jest、PyTest、JUnit用例,覆盖边界与异常;套餐按季/年灵活付费,额度分时恢复,个人团队皆可把GLM Coding当作“统一大脑”,成本比单买各工具省70%,让写、读、查、优全栈流程全面提速。
GLM Coding官网 : https://bigmodel.cn/glm-coding
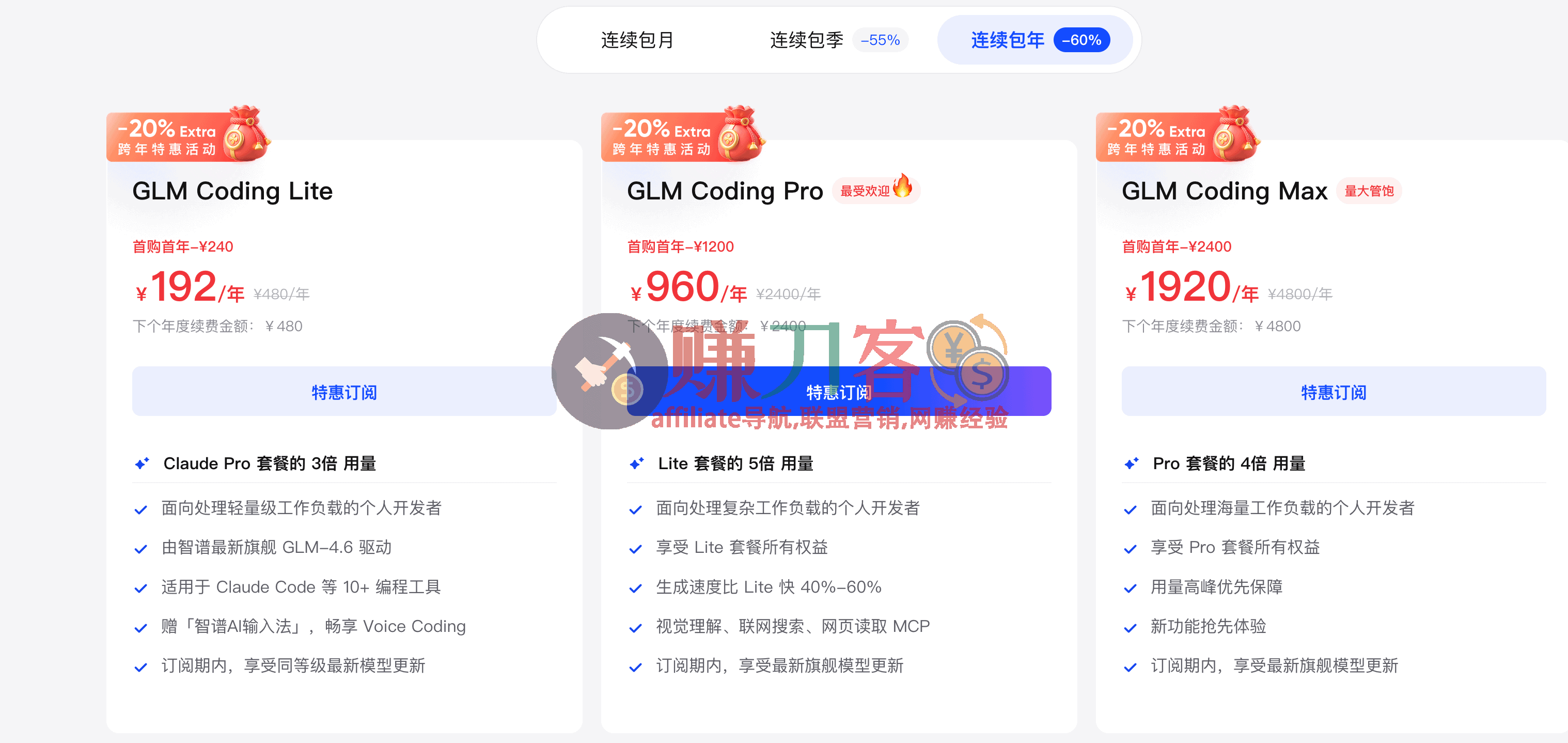
最新GLM Coding优惠码2026
GLM Coding Plan·跨年特惠
12.08-01.15:50% 首购立减 + 额外节日限定优惠 年付套餐仅需192元/年!
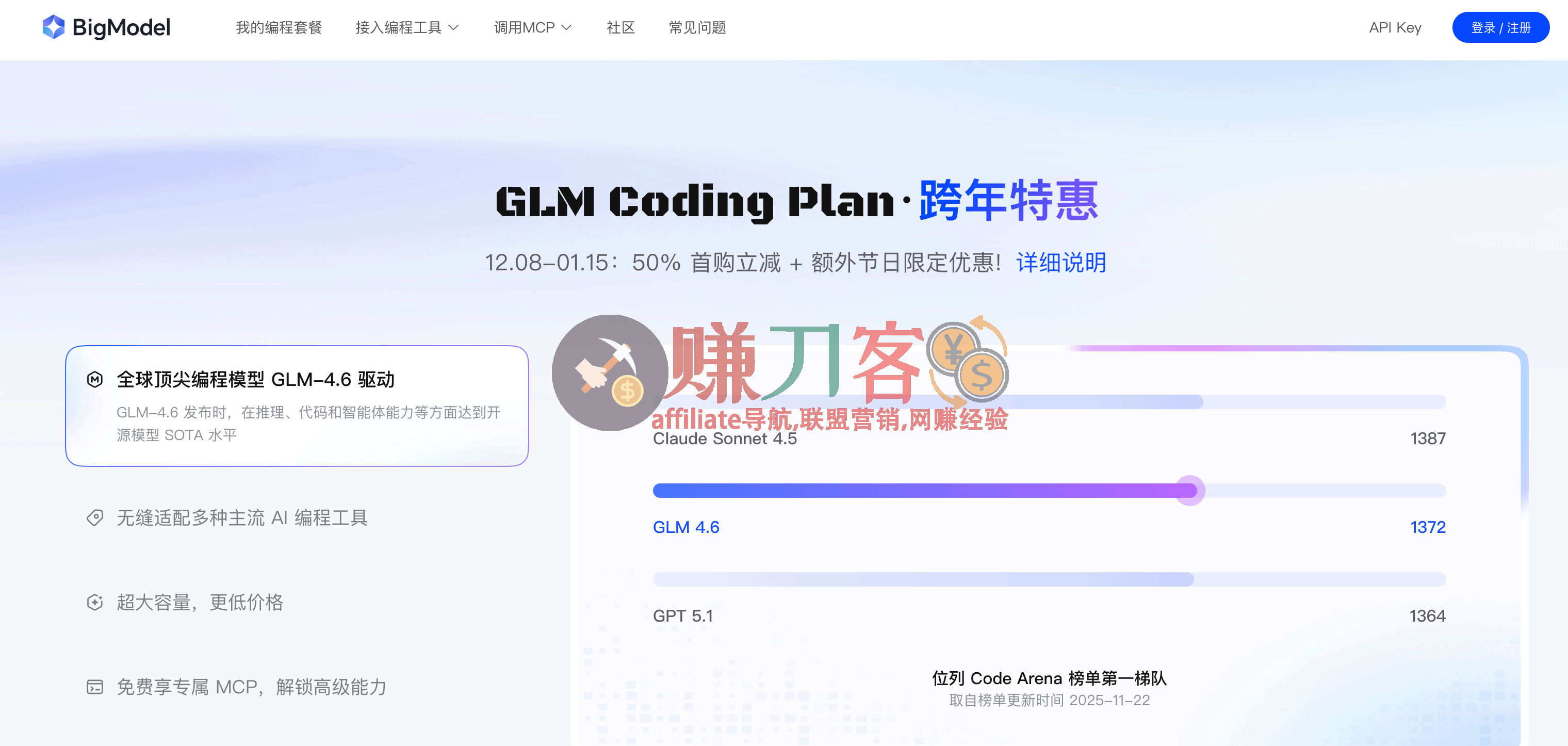
GLM Coding(主要指 GLM-4 / GLM-4.5 在编程场景的应用)目前已经进入“可和一线闭源模型拼刺刀”的阶段,在代码生成与智能开发辅助领域具备非常高的性价比和实用价值。
一、GLM Coding 是什么?
GLM 源自清华大学知识工程实验室与智谱 AI 的“通用语言模型(General Language Model)”系列,GLM-4/4.5 是 2024–2025 年迭代出的新一代模型,重点强化了推理、代码和工具调用等能力。
在官方定位中,GLM-4.5 被明确强调为“Reasoning, Coding, and Agentic Abilities”,编码能力是其三大核心卖点之一。
如果把 “GLM Coding” 狭义理解,可以包括三层:
- 以 GLM-4 / GLM-4.5 为核心的大模型,在各类 IDE、终端、浏览器等场景里做“智能编程助手”。
- 围绕代码任务做的能力增强:函数调用、多轮工具调用、长上下文代码理解、测试样例生成等。
- 在实际开发流程(写代码、查 bug、重构、Review、生成脚手架)中的整合与落地方式。
二、主要功能与核心特性
1. 代码生成与补全
GLM-4/4.5 在多项编程相关基准测试中表现接近甚至逼近 GPT-4 系列,普通开发者在真实体验中的差距已经非常小。
- 多语言代码生成:主流支持 Python、Java、C/C++、Go、Rust、JavaScript/TypeScript、SQL 等,且能够在跨语言重写(如 Python→Go)中保持较好的一致性。
- 语义级自动补全:在编辑器中可基于函数注释、上下文调用链自动生成函数体,而不是简单的“下一行预测”。
结合 128K 量级的上下文(具体取决于具体部署版本),GLM 可以一次性读入一个中大型服务的关键模块,对“在某个业务路径下我需要怎么修改这一段代码”这类任务有明显优势。
2. 代码理解与重构
对于已有代码库,GLM Coding 的典型用法包括:
- 解释复杂逻辑:通过自然语言描述某段函数或模块的职责、输入输出、边界情况和潜在风险点。
- 自动重构:在保持行为一致的前提下,对冗长函数进行拆分、对重复逻辑进行抽象、引入设计模式等。
不少开发者在实践中反馈,开源系模型(含 GLM)在 50–60% 的日常工作(增量开发、调 bug、写脚本)上已经“够用”,真正需要顶级闭源模型的是特别复杂的系统级设计与高难度算法题。
3. 调试、测试与 Bug 定位
相较传统“代码生成器”,GLM 更像“智能 Pair Programmer”:
- 根据错误日志和堆栈信息分析可能的根因,给出多种修复方案,并指出风险较小的改法。
- 自动生成单元测试和集成测试案例,覆盖正常路径和常见边界条件,甚至可以模仿现有测试风格写出同一套测试框架下的用例。
在一些比较系统的实验中,引入类似 GLM-4 的 AI 编程助手后,代码生成效率相比传统方式提升可达 30–100 倍,这个量级基本来自批量写样板、生成测试以及自动改错。
4. 工具调用与 Agent 能力
GLM-4.5 官方强调其工具调用成功率达到 90.6%,在多模型对比中处于前列,这对于复杂开发任务非常关键。
- 多步工具调用:可以先调用“代码搜索 API”定位相关文件,再调用“编译/测试工具”验证修改,最后汇总结果给开发者。
- 结构化输出:通过 JSON schema 约束返回结果,使得 AI 改代码后可以被 CI 流水线自动消费,例如自动生成修复 PR 描述、Changelog 等。
在一些自动化任务测试(如 TAU-Bench)中,GLM-4 在零/少样本任务自动化方面表现优异,这也为“自动修 Bug + 自动回归测试 + 自动提 PR”这类 agent 流程提供了能力基础。
5. 长上下文与多模态(视版本而定)
- 长上下文:GLM-4/4.5 的部分配置支持 128K 上下文,专门面向大项目代码库的理解与跨文件重构场景。
- 多模态:GLM-4.5V 等多模态版本可处理文本 + 图像输入,理论上可以解释架构图、时序图,甚至对截图中的报错信息做分析。
对于独立站技术博主,这意味着可以直接上传一张系统架构图,让模型根据图和代码一起分析瓶颈或优化点,在写架构设计类内容时非常实用。

三、实际测评:GLM Coding 在真实开发中的表现
1. 算法与刷题场景
在算法题(类似 IOI、ACM 题型)上,当前综合表现最好的是 GPT-5.2 一类最新高端模型,但 GLM-4 点击率和表现都非常稳健。
在典型评测中可以观察到:
- 中等难度的算法题:GLM 往往能一次性产出可用解,包括完整的边界处理和复杂度控制。
- 高难度题目:会出现逻辑漏洞或复杂度不达标的情况,需要开发者自己有一定鉴别能力和重构能力,这一点和其他主流模型的行为类似。
从博主视角写教程时,可以把 GLM 作为“算法解题伙伴”:先由它起草解法(含时间空间分析),再由人工补充更贴地气的讲解和坑点提示。
2. Web / 全栈开发
在 Web / 全栈场景,GLM 的优势相对更明显:
- 快速脚手架:为前后端项目生成初始目录结构、配置文件和核心路由逻辑,例如 React + Node.js + PostgreSQL 的标准模板。
- 业务逻辑协作:根据自然语言描述,直接生成 CRUD 接口、DTO、ORM 模型和基础校验逻辑,并同时产出文档注释/Swagger 定义。
实际体验中,GLM+Git/CI 的组合可以让个人博主在搭一个新产品型站点时,前几天的“基础工程建设时间”压缩一半以上。
3. 旧项目维护与迁移
对于很多中文独立站博主来说,一个现实问题是:手里有一堆 PHP/WordPress 或老版 Laravel 项目,需要缓慢演进、重构甚至迁移语言栈。
GLM 在长上下文 + 中文语义理解上有一定优势,非常适合做这类工作:
- 大段注释和 README 均为中文时,模型对业务含义理解更加自然,画错的“业务意图”明显减少。
- 在迁移时(例如 PHP → Go / Node),可以同时考虑“原先是怎么处理人民币金额、时间格式、本地化”等一系列与中文业务高度相关的问题。
有评估指出,GLM-4.6 在综合能力上略逊于最强的 Qwen / Kimi,但在中文编程场景中仍是“十分可靠且成本可控”的选择。
四、GLM Coding 的适用人群与场景
1. 面向个人开发者 / 独立站站长
- 低成本高体验:相对于最新一代 GPT-5.2 等闭源旗舰,GLM 系列在费用上往往更有优势,尤其在大上下文场景;从 Galaxy 等第三方对比可见,GLM 在同等场景下 Token 成本往往低一个量级。
- 中文体验友好:对于完全用中文描述需求、提交注释和 README 的项目,GLM 的理解准确度和沟通效率表现良好。
2. 面向小团队 / 初创公司
- 可做内部“编程中枢”:通过函数调用和工具编排,把 GLM 嵌入到 CI/CD、监控告警、代码审查流程中。
- 合规与数据可控:相较于完全托管在海外闭源平台,使用国产模型(含企业部署版本)在数据合规和内网部署上更容易实现。
3. 教学与内容创作者
对于做中文技术博客的创作者,GLM Coding 有两类主要价值:
- 作为写作助手:快速生成示例代码、伪代码、教学脚本、练习题及答案解析;在写多语言对比教程时尤其省时间。
- 作为“案例工厂”:按照指定技术栈和业务场景(电商、SaaS、订阅、独立站)自动生成项目案例,再由博主进行筛选和修改后分享。
五、五款主流 Coding 模型详细对比
下面选取 5 个在 2024–2025 年广泛用于编程的模型:GLM-4.5、GPT-5.2、Claude 4.x、Kimi K2、DeepSeek V3/R1,从多个维度进行对比。为了便于阅读,将 DeepSeek V3/R1 视作一类(重点在开源+推理)。
1. 能力与定位概览
| 维度 | GLM-4.5 | GPT-5.2 | Claude 4.x | Kimi K2 | DeepSeek V3/R1 |
|---|---|---|---|---|---|
| 核心定位 | 中文友好、推理+Coding+工具调用 | 旗舰级通用模型,综合最强 | 安全&合规为核心,长文档与复杂推理强 | 数学 & 编程强,偏金融/技术垂直 | 强推理开源系代表,成本低 |
| 编程能力 | 接近 GPT-4 级别,日常开发足够 | 目前综合最强,尤其在复杂算法与系统设计 | 真实项目场景表现优秀,稳健且安全策略好 | 代码&数学领域成绩突出,适合高精度领域 | 常规编码强,复杂推理有优势,个别版本对代码略有波动 |
| 语言优势 | 中文为主,兼顾英文 | 英文最佳,中文也很强 | 英文优,中文稳步提升 | 针对中文及特定行业语料增强 | 中英都可,偏工程 & 技术社区语料 |
2. 基准测试与实战表现
综合多个 2025 年的榜单与测评,可以抽象出以下趋势:GPT-5.2 在综合编码基准上领先;但在日常开发体验上,GLM、Kimi、DeepSeek 等已经非常接近,主要差别体现在极限场景。
| 指标 | GLM-4.5 | GPT-5.2 | Claude 4.x | Kimi K2 | DeepSeek V3/R1 |
|---|---|---|---|---|---|
| LiveCodeBench(日常题) | 高分段,略低于最新 GPT 系列 | 排名前列,日常开发体验最佳之一 | 略低于 GPT,但表现稳定 | 在数学/代码子集上非常强 | 部分版本接近商业模型顶尖水平 |
| IOI / 算法深度 | 接近 GPT-4,略逊 GPT-5.2 | 目前最强之一,极高 | 与 GPT-4 同一梯队 | 在数学+编程混合题上表现突出 | 推理模式强,但个别评测指出编码版本存在不稳定情况 |
| SWE-bench(实战修 Bug) | 强,接近 GPT-4 级别 | 涉及真实仓库任务时表现领先 | 表现很强,侧重安全和稳健修改 | 在涉及金融/高可靠领域任务表现好 | 实测中不如 GPT-4.1 等商业顶级模型,但胜在开源和成本 |
3. 上下文长度、多模态与工具调用
| 维度 | GLM-4.5 | GPT-5.2 | Claude 4.x | Kimi K2 | DeepSeek V3/R1 |
|---|---|---|---|---|---|
| 上下文长度 | 部分配置可达 128K | 新一代模型大多支持长上下文(具体取决于版本) | 以超长上下文见长,200K 级别已广泛提及 | 上下文充足,应对多文档任务能力佳 | 部分版本上下文较长,适合代码库场景 |
| 多模态 | GLM-4.5V 支持图像+文本,对报错截图/图表等有用 | 文本+图像+语音等多模态支持强 | 文本+图像能力强,适合复杂文档阅读 | 对数学图表、技术文档有针对性优化 | 新版本也在支持图像,多模态逐渐增强 |
| 工具调用 | 官方公布工具调用成功率高达 90.6%,在多模型中居前 | 对函数工具、代码执行环境的集成非常成熟 | 在受控环境中调用工具时强调可解释性与安全 | 对特定行业 API 集成好,适合垂直场景 | 开源生态下工具接入灵活,适合自建平台 |
4. 成本与部署方式
| 维度 | GLM-4.5 | GPT-5.2 | Claude 4.x | Kimi K2 | DeepSeek V3/R1 |
|---|---|---|---|---|---|
| Token 成本 | 相比 GPT-4/4.1,价格显著更低,性价比高 | 旗舰级定价,相对较贵 | 中高价位,强调企业级服务与合规 | 在高精度场景中性价比不错 | 开源/商用混合,有极具竞争力的性价比 |
| 自建/私有化 | 支持企业级私有化部署,适合本土合规需求 | 以云端托管为主,私有化门槛高 | 企业级私有部署选项主要面向大型客户 | 以云服务为主,特定大客户可定制 | 开源模型可在本地/私有云灵活部署 |
| 适合对象 | 中小企业、个人站长、重视中文生态的团队 | 预算充足、追求能力天花板的团队 | 高合规行业(医疗、金融、法律) | 对数理/金融精准度要求极高的团队 | 技术型团队、对成本敏感、愿意自己运维 |
5. 对中文开发者的友好度
- GLM-4.5:以中文为第一公民,中文文档理解、中文注释代码生成、中文需求分析的体验很自然,适合中文互联网环境下的独立站开发者。
- Kimi K2:对中文数据和本土行业知识有针对性训练,在涉及复杂数学和财务建模的任务中尤其出色。
- DeepSeek:社区活跃,大量中文技术讨论和实践案例,非常适合喜欢折腾的工程师群体。
总的来看,若主要开发语言为中文,且项目用户以中文为主,GLM 和 Kimi 的整体体验往往比“只为能力顶峰买单”的 GPT-5.2 更加均衡。
六、面向中文独立站博主的实践建议
1. 写代码时如何让 GLM 发挥最大价值
- 需求描述尽量结构化:比如“技术栈 + 业务目标 + 约束条件 + 已有代码链接”,能大幅提高 GLM 一次性给出可用方案的概率。
- 让它补充而不是“接管”:可以让 GLM 给出整体方案和关键代码,由自己做最后的架构决策和安全审查,这样既省时间又不会失去对代码库的掌控感。
2. 写技术博客时的用法
- 生成示例与对比代码:在同一篇文章里展示“传统写法 vs 优化写法”,可以让 GLM 先给出多个版本,再人工挑选与润色。
- 生成练习题与答案:针对某个知识点(例如“Go 的 Context 使用模式”),让模型生成 5–10 道练习题及解析,有助于提高文章教学价值。
3. 与其他模型混合使用
- 用 GLM 做日常开发与中文内容生产,用 GPT-5.2 或 Claude 处理极高难度的算法题和复杂跨领域推理解题,这是一种在成本与能力之间折中非常好的“组合拳”。
- 在涉及深度金融建模、复杂数学推导时,可以考虑引入 Kimi K2;在需要强开源生态和自建环境时,用 DeepSeek 系列做一部分工作,再通过 GLM 做中文场景优化。
七、小结:GLM Coding 的定位与未来空间
GLM-4/4.5 在 2025 年的编码生态中,已经从“追赶者”变成了实际可用、性价比极高的主力选择之一。
在综合能力上,顶级旗舰如 GPT-5.2 仍然占据绝对高地,但对于大多数中文独立站博主、自由开发者和中小团队来说,GLM 提供了足够强的编码能力、更友好的中文交互体验和更可控的成本结构。
如果从“独立中文博客+独立站开发”的场景出发,GLM Coding 很适合作为日常的编码助手与内容创作伙伴,再辅以其他几款头部模型,在能力天花板、成本和中文体验之间取得一个非常实用的平衡。





评论